为什么要了解内存访问的底层
在操作系统的抽象下,内存资源似乎给用户程序一种统一无差异访问的理想状态,但是在编程中并不是如此。一个load和store指令理论上只会操作一个字的数据,但是内存往往不会只返回一个字的数据给CPU,反而是一个cache-line粒度的来填充cache再给CPU操作。假设我们每次都随机访问一个字的数据,那么总延迟就是内存多次传输cache-line的延迟之和。如果我们将多字节的数据控制在一个cache-line的大小内进行统一访问,传输延迟就只有内存传输一次的延迟。这个差异还是挺大的,所以在程序设计中利用好这一点就能提高程序的性能。编程就要对所用硬件的特性有所了解进行针对性优化,而不能全交给操作系统管理,这点和面向块设备对程序进行针对性优化也是类似的。
CPU访问数据
CPU通过load和store指令来进行内存数据的加载和写入,粒度最大为一个字。由于CPU缓存机制的存在,load和store指令会先在CPU cache中进行目标地址数据查找,没有的话再从内存中加载到cache中。由于数据具有局部性访问特点,即可能会访问到邻近数据,所以加载的时候会加载一个cache-line(64字节)的数据而不仅仅是一个字
内存硬件架构
DRAM内存在逻辑使用上为用户程序提供能够点对点进行字节粒度的存储的能力,就好像每次访问都是可以访问一字节的数据一样。其实在底层硬件设计并不是如此,其硬件设计只是向上抽象提供了这样一个功能。
DDR3内存条的硬件设计架构如下:
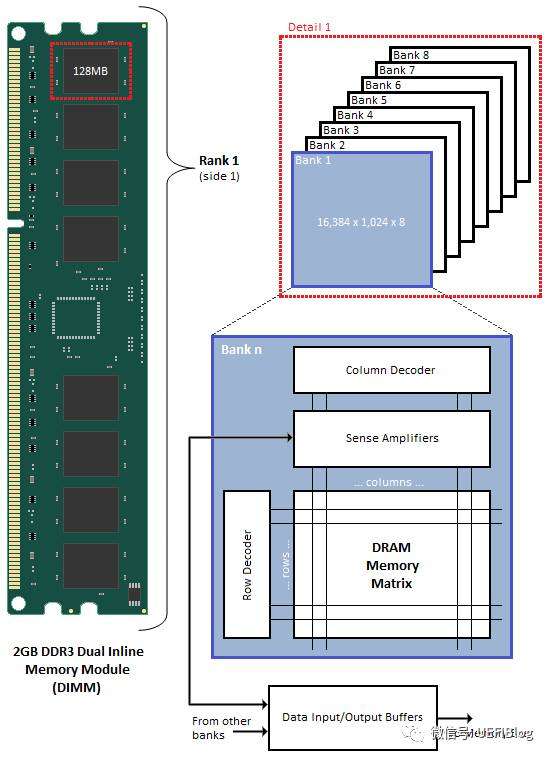
从硬件设计结构上其由大到小划分为:
- Memory Module(内存条)
- Chip(存储芯片)
- Bank(芯片内的逻辑存储单元)
- Row和Column(Bank内的定位方式)
一个chip一般由8个bank组成,每个bank是一个存储矩阵,每个格子存储一个字节的数据。所以8个bank每个相同位置的格子组合起来就是8字节的数据,即一次数据传输的数据量。所以8字节的数据其实是由一个chip的8个bank的字节组合而成,提高存储的吞吐量。
内存硬件访问流程
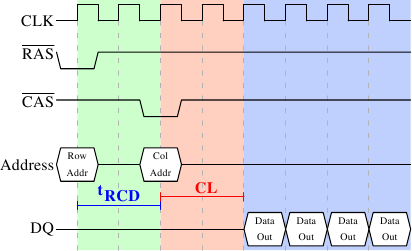 如上图所示,在内存时钟周期中,每次存储请求都要通过RAS和CAS控制信号进行选行和选列,这两个控制信号都有一点延迟,然后才是数据传输,如上图一个周期可以传输一个字的数据(也可以传两个)。
如上图所示,在内存时钟周期中,每次存储请求都要通过RAS和CAS控制信号进行选行和选列,这两个控制信号都有一点延迟,然后才是数据传输,如上图一个周期可以传输一个字的数据(也可以传两个)。
既然数据的传输需要这么多的准备工作,仅仅传输一个字显然是太浪费了。因此,DRAM模块允许内存控制指定本次传输多少数据。可以是2、4或8个字。这样,就可以一次填满高速缓存的整条线,而不需要额外的RAS/CAS序列。另外,内存控制器还可以在不重置行选择的前提下发送新的CAS信号。
为了不浪费内存的控制信号延迟,内存底层以块为粒度进行数据传输的,一个load操作会传输一个块为64字节(一个cache-line)到cache中,数据总线要传输8次。这就和上面的cache的操作联系起来。
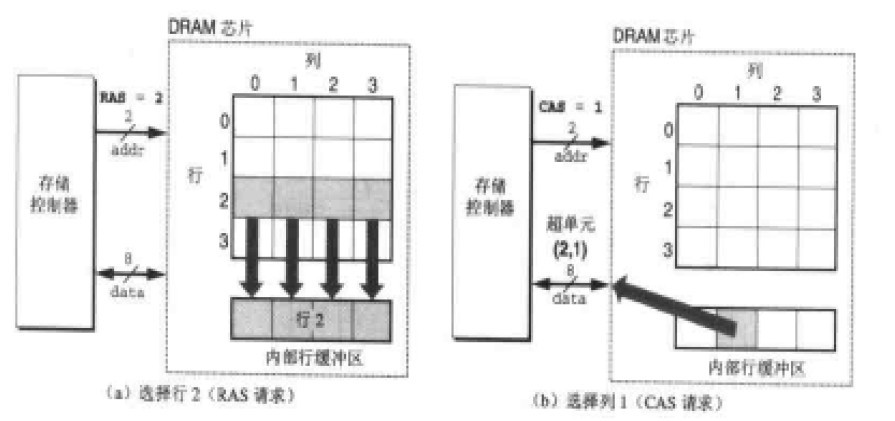
在内存中也就会存在内存行缓冲区,一次RAS信号就把一行的数据放入缓冲区,然后通过CAS信号返回对应的数据即可,如下所示:
为什么要内存对齐
由上可知,内存的访问是以8个分裂的字节拼接成一个单元再返回的。内存地址对齐的话,比如数据为一个字即8字节,那么CPU访问这个数据只需一个load/store指令即可完成。假设内存地址不对齐,那么这段访问代码就会被汇编成两个load/store操作,分别取位于两块内存单元上的两部分数据然后在寄存器中进行拼接,产生较大的访问代价。如MIPS指令集下非对齐访问。对于X86等CISC指令集支持CPU对非对齐的内存地址的访问,通过CPU内微码实现,效率大大降低。
对齐规则
有效对齐值
- 数据类中自身对齐值:如int为4字节,char为1字节
- 指定对齐值:#pragma pack(value)指定value为指定对齐值
- 结构体或者类的自身对齐值:MAX(成员变量自身对齐值)
- 数据成员,结构体和类的有效对齐值:MIN(自身对齐值,指定对齐值)
根据上面规则得出的有效对齐值N就是对齐规则中真正用于对齐的值
内存地址分配步骤和规则
- 结构体变量的首地址是有效对齐值N的整数倍
- 每个成员起始地址满足:起始地址%N=0,如有需要编译器会在成员间加上填充字节
- 结构体的总长度是结构体有效对齐值N的整数倍:结构体总大小%有效对齐值=0,如有需要编译器会在最后一个成员加上填充字节
- 结构体内类型相同的连续元素将在连续的空间内,和数组相似